


Last year, the number of email users reached some 4.2 billion– over half of the global population. In fact, on average, people have two email accounts; and they rarely switch email providers or change usernames. So what does this mean when it comes to your fraud risk assessment? Simple. Email-to-Name match can – and should – be factored into customer data verification.
The Ekata Identity Graph is a sourced, licensed, and authoritative digital identity data asset that can validate if the email address provided in the transaction is associated with the customer name or not. If someone doesn’t have access to the Ekata Identity Graph, it is still possible to measure the similarity of the name and the email address. This can be done using the Levenshtein distance.
This Levenshtein distance – or edit distance – is a string metric for measuring the difference between two sequences; a higher score means a larger “distance” between the strings. It is called an edit distance because it measures how many edits would be needed to transform string one to string two.
The Levenshtein distance, which is one type of edit distance, is the smallest number of edits required to transform one string into another. In this situation – using Ekata Identity Graph – the Levenshtein distance is between the name and email address. An “edit” is defined by either an insertion of a character, a deletion of a character, or a replacement of a character.
Let’s consider the name John Doe and the email addresses john.doe@example.com and test123@example.com. You can use the Levenshtein distance to measure how similar ‘john doe’ – the normalized version of the original name ‘John Doe’ – is to the local part of the email addresses (everything before the @ sign) – to ‘john.doe’ and ‘test123’, respectively.

The difference between ‘john doe’ and ‘john.doe’ is small, with only one replacement needed for the transformation, so it results in a low Levenshtein distance value. The difference between ‘john doe’ and ‘test123’ is large, with seven replacements and one deletion needed for the transformation, so it results in a high Levenshtein distance value.
What does the data tell us?
As the figure below shows, the Levenshtein distance* between the name and the email address makes good differentiation between the fraudulent and non-fraudulent transactions.
The x-axis shows the bucketed Levenshtein distance of the email-name pairs, whereas the y-axis shows the number of transactions falling in a particular bucket. The orange line represents the reject rate, forming a reasonable relationship; the higher the distance, the higher the risk.
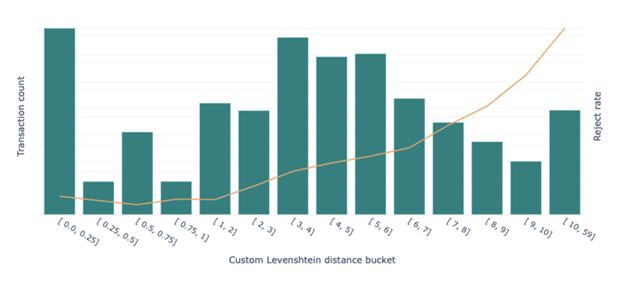
*Instead of the standard version, a custom Levenshtein distance is used where different weights are assigned to the different “edit” operations.
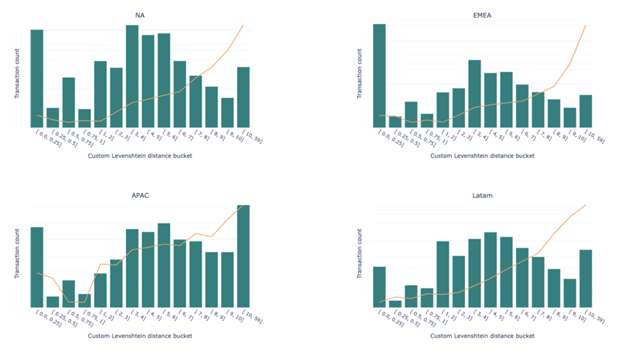
Regardless of the region and linguistic characteristics, high email-name Levenshtein distances are much more likely to be fraudulent, as the figures below show.
Final thoughts
Although a static email-to-name relationship is not enough to make a final decision regarding customer data verification, it is a vital consideration. Indeed, being on the lookout for suspicious username selection and automatically generated accounts is often one of the first steps in any successful fraud risk assessment that a merchant can take.
The Ekata Identity Engine consists of two data sources, the Ekata Identity Graph and Ekata Identity Network. It seamlessly captures the behaviors and dynamic relationships of the different digital identity elements. Our fraud risk assessment models are able to identify what fraud looks like for different businesses, enabling our customers to stop fraud before it takes hold.
To learn more about how Ekata can help identify your good customers and combat fraud, visit Ekata.com today.


